Last Updated on May 27, 2022
Learn an algorithm in autodidact is time-consuming; especially for people who are not interested in mathematics. Because, sometimes we don’t know that “we don’t know”, many things. Including when studying the Expectation – maximization (EM) Algorithm. Therefore, I could improve your understanding of the EM algorithm in this article, and I hope you can easily understand it.
EM algorithm often used in machine learning as an algorithm for data clustering.[1], [2] Sometimes, one of the clustering problems is when the data doesn’t have any labels. For example, if we know A in the data, then we can calculate B from the data; or vice versa, if we know B, we can calculate A. However, sometimes we have mixed data, and the label of A and B are unknown. In this case, the EM algorithm could help to solve the problem.[3]
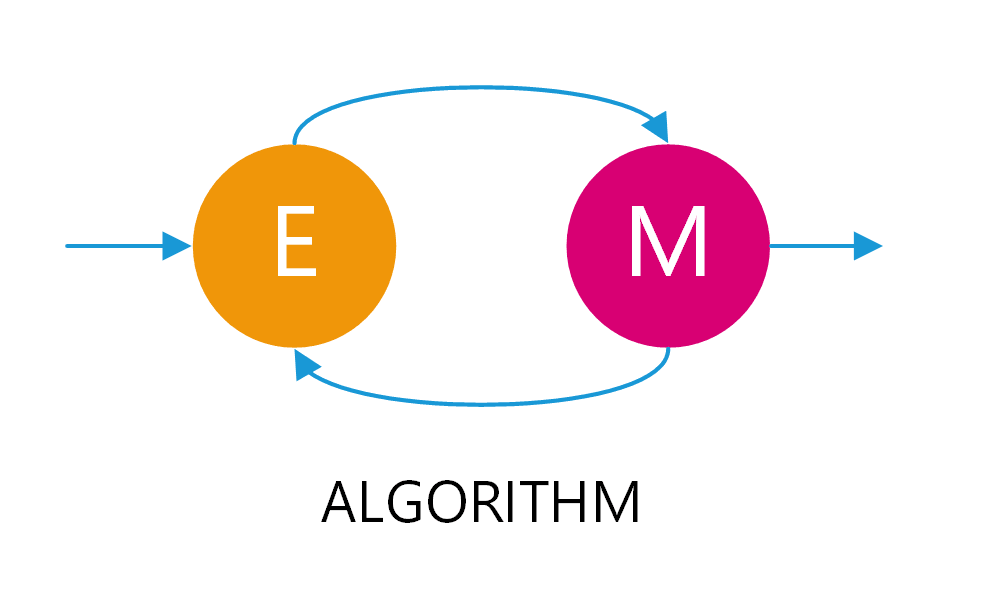
For a summary, the EM algorithm is an iterative method, involves expectation (E-step) and maximization (M-step); to find the local maximum likelihood from the data. Commonly, EM used on several distributions or statistical models, where there are one or more unknown variables. Therefore, it called missing or “latent” variables.
In other words, we can use the EM algorithm if:
- We have incomplete datasets (for example, it doesn’t have groups or labels in the data), but we need to predict its group or label.
- The group or label has never been observed or recorded but is very important in explaining the data. It called a “latent” variable, meaning missing, hidden, or invisible.
Note: Some theories that you may need to learn are: the probability of binomial random variable and conditional probability.
Case example for EM Algorithm
To easily understand the EM Algorithm, we can use an example of the coin tosses distribution.[4]

For example, I have 2 coins; Coin A and Coin B; where both have a different head-up probability. I will randomly choose a coin 5 times, whether coin A or B. Then, each coin selection is followed by tossing it 10 times. Therefore, we have the following outcomes:
- Set 1:
H T T T H H T H T H(5H 5T) - Set 2:
H H H H T H H H H H(9H 1T) - Set 3:
H T H H H H H T H H(8H 2T) - Set 4:
H T H T T T H H T T(4H 6T) - Set 5:
T H H H T H H H T H(7H 3T)
From the fig. 1 above, the “image” side denoted by “H” or Head-up, and the “number” side denoted by “T” or Tail-up. Then, the probability of coin will land with head-up for each of these coins, could be denoted as theta or “ “.
“.
The question is, how do you estimate for each coin?[5]
Completed data
In different cases, with the same outcomes as above; I give you more information. I told you which coins I used for each set; means the coin identity. Then, the data you have will be like this:
- Set 1, Coin B:
H T T T H H T H T H(5H 5T) - Set 2, Coin A:
H H H H T H H H H H(9H 1T) - Set 3, Coin A:
H T H H H H H T H H(8H 2T) - Set 4, Coin B:
H T H T T T H H T T(4H 6T) - Set 5, Coin A:
T H H H T H H H T H(7H 3T)
Because you already have all the data you need, you can easily calculate the probability of getting head-up on each coin. Therefore, the calculation of will be:
By knowing the result of coin A = 24H 6T, in 3 sets with a total of 30 tosses, then  .
.
Similarly to the result of coin B = 9H 11T, in 2 sets with a total of 20 tosses, then  .
.
This simple equation is known as Maximum Likelihood Estimation (MLE), Where  .
.
The overview of EM algorithm
Overall flowchart
Before returning to the original case, let me explain briefly the stages of the EM algorithm. So you have an overall picture of the EM algorithm flow, which helps you reading until the end.

There are several steps in the EM algorithm, which are:
- Defining latent variables
- Initial guessing
- E-Step
- M-Step
- Stopping condition and the final result
Actually, the main point of EM is the iteration between E-step and M-step, which could be seen in Fig. 2 above. The E-step will estimate your hidden variables, and the M-step will re-update the parameters, based on the estimation of the hidden variables. In other words, this iteration aims to re-improve the estimation of current parameters.
Inside the EM algorithm

Take a look at Fig 3 above, to see what EM really does in your case; where you don’t know the coin identity. The current approach is to distribute the number of heads for each set; proportionally based on the parameter for each coin. Therefore, first, you need to guess the initial parameter [Fig 3(1)] for each coin. Then, (in the beginning) the current parameters [Fig 3(2)] are your guessing.
Next, in the E-step, you could calculate each coin’s probability to get the outcomes of each set [Fig 3(3)]; based on the current parameters. For example, the probability of coin A to get 8H 2T in 10 tosses (set 3).
Then, compare the probabilities both coin A and coin B; based on their total probability [Fig 3(4)]. For example, the result for a set with 8H 2T, I have a 73% probability using coin A, compared to 27% using coin B. This is how you estimate the probability of coin identity used in each set.
Then, the estimated identity is used to estimate the number of heads (and tail) for each coin, for each set [Fig 3(5)]. For example, those 8 Heads divided proportionally 73% to coin A and 27% for coin B.
Finally, the estimation of total heads of each coin is used to recalculate the value of the parameters at the M-Step. This re-calculation will improve the current [Fig 3(2)]. In other words, this re-calculation is based on the estimated results of hidden variables and observable data.
This iteration will continue until reaches the “maximum iteration” limit or convergence threshold reached. When the iteration stopped, the final results obtained are the closest estimation to the local optimum solutions.
1. Defining latent variables
Now, back to the original case, where the outcomes you have are:
- Set 1:
H T T T H H T H T H(5H 5T) - Set 2:
H H H H T H H H H H(9H 1T) - Set 3:
H T H H H H H T H H(8H 2T) - Set 4:
H T H T T T H H T T(4H 6T) - Set 5:
T H H H T H H H T H(7H 3T)
First, you must define what variables are required; but are not observed in the data.
The goal is to estimate the probability of getting heads-up for each coin. However, it cannot be calculated directly; if you don’t know the identity of the coin used in each set. Therefore, it is necessary to know which coin is used in each set. In other words, this coin identity is your latent variable.
Right now, besides the 5 sets of outcomes above, you only know that I used two coins; which are coin A and coin B.
2. Initial guessing
As stated before, the probability of getting head-up for each of these coins denoted as theta or . Currently, there are only coin A and coin B; with unknown parameter values of  and
and  .
.
Then, before estimating with EM iteration, you need to provide an initial estimate to both parameters [Fig 3(1)]. Therefore, you may choose randomly for each . For example, you may set is  , or else, it’s up to you; as well as .
, or else, it’s up to you; as well as .
By the way, please noted that there is no relationship between parameters guessing; both and . For example, if you think that the sum of and must be = 1, NO!. This probability represents the individual value of getting heads-up on each coin.
 , meaning that there is 60% probability of getting head-up, compared to 40% probability of getting tail-up using coin A. It has nothing to do with guessing the value of or for coin B. So even though you already set the initial of , you may set with
, meaning that there is 60% probability of getting head-up, compared to 40% probability of getting tail-up using coin A. It has nothing to do with guessing the value of or for coin B. So even though you already set the initial of , you may set with  ,
,  ,
,  ,
,  or any number you want between 0 and 1.
or any number you want between 0 and 1.
Okay enough. Now, let’s say you have randomly set both initial values, which are:
 and
and 
3. E-Step
Now you have the required variables. So, you can start estimating the identity of the coin used in each set.
Each set, which contains the outcomes of heads and tails, can be denoted by  notation. Then, the probability of “using coin A” denoted as
notation. Then, the probability of “using coin A” denoted as  , and the probability of “using coin B” denoted as
, and the probability of “using coin B” denoted as  .
.
The probability a coin giving E
At the beginning of E-Step, you need to know the probability of a set using coins A or B. Take an example from set 3, where = HTHHHHHTHH (8H 2T). If , it means the probability of getting head is  (and tail ) uses coin A. Then, how much probability of coin A will give
(and tail ) uses coin A. Then, how much probability of coin A will give  in 10 tosses (a set)? This is what we need to estimate first [Fig 3(3)]. Then, this probability can be denoted by
in 10 tosses (a set)? This is what we need to estimate first [Fig 3(3)]. Then, this probability can be denoted by  .
.
Similarly, the probability of coin B giving  , could be denoted by
, could be denoted by  . This actually relates to the probability distribution of a binomial random variable, which equation is:
. This actually relates to the probability distribution of a binomial random variable, which equation is:

where:
 = the probability of coins x gives .
= the probability of coins x gives . = total coin tosses in a set .
= total coin tosses in a set . = total number of heads in a set of .
= total number of heads in a set of . = the probability of getting head-up using coin x.
= the probability of getting head-up using coin x.
Then, we can calculate the probability of getting using coins A and B as follows:
![P(E_{8H2T}|Z_{A})= \dfrac{10!}{8!\;2!}\;{0.6}^{8}\;0.4^{2}=0.121 \\[4pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-66117536e7b0bcc9c6a5c4da3558cac0_l3.svg "Rendered by QuickLaTeX.com")

The ratio of coins A and B gives E
Next, you can compare the probabilities both of coin A and coin B give [Fig 3(4)]. So, according to Bayes’ theorem and the law of total probability, we can determine the ratio of probability using the following equation:[6]
![P(Z_{x}|E)= \dfrac{\textit{the probability of coins x giving E using}}{\textit{total probability of coins x and y in giving E}} \\[12pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-1e862bf63073b196bcf608687fca3aa7_l3.svg "Rendered by QuickLaTeX.com")
![P(Z_{x}|E)= \dfrac{P(E|Z_{x})P(Z_{x})}{P(E|Z_{x})P(Z_{x})+P(E|Z_{y})P(Z_{y})} \\[8pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-bce552ce1a85d4df2e62b31fffa7da28_l3.svg "Rendered by QuickLaTeX.com")
where:
 = the probability of coin x giving (compared to coin y).
= the probability of coin x giving (compared to coin y). = the probability of choosing coin x. = the probability of choosing coin y.
= the probability of choosing coin x. = the probability of choosing coin y.
However, because our case is only using 2 coins, coins A and B, then the probability that I will choose one of them is  . Then
. Then  .
.
Accordingly, for coin A, we can simplify the equation above into:
![\begin{aligned}P(Z_{A}|E) &= \dfrac{P(E|Z_{A})\cancel{P(Z_{A})}}{P(E|Z_{A})\cancel{P(Z_{A})}+P(E|Z_{B})\cancel{P(Z_{B})}} \\[12pt] &= \dfrac{P(E|Z_{A})}{P(E|Z_{A})+P(E|Z_{B})} \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-54c5a1f58afd9deb993e9c109afb5038_l3.svg "Rendered by QuickLaTeX.com")
![\begin{aligned} P(Z_{A}|E_{8H2T}) &= \dfrac{\cancel{\dfrac{10!}{8!\;2!}}\;{0.6}^{8}\;0.4^{2}}{\cancel{\dfrac{10!}{8!\;2!}}\;{0.6}^{8}\;0.4^{2}+\cancel{\dfrac{10!}{8!\;2!}}\;{0.5}^{8}\;0.5^{2}} \\[24pt] &= \dfrac{{0.6}^{8}\;0.4^{2}}{{0.6}^{8}\;0.4^{2}+{0.5}^{8}\;0.5^{2}} \\[12pt] &= 0.73 \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-855d9ea630e406925cd3297c6eb38bb2_l3.svg "Rendered by QuickLaTeX.com")
Similarly, for coin B, become:
![\begin{aligned} P(Z_{B}|E_{8H2T}) &= \dfrac{\cancel{\dfrac{10!}{8!\;2!}}\;{0.5}^{8}\;0.5^{2}}{\cancel{\dfrac{10!}{8!\;2!}}\;{0.6}^{8}\;0.4^{2}+\cancel{\dfrac{10!}{8!\;2!}}\;{0.5}^{8}\;0.5^{2}} \\[24pt] &= \dfrac{{0.5}^{8}\;0.5^{2}}{{0.6}^{8}\;0.4^{2}+{0.5}^{8}\;0.5^{2}} \\[12pt] &= 0.27 \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-e5903f648cb1dd3c03ee4b080b46879f_l3.svg "Rendered by QuickLaTeX.com")
Estimates the number of heads for each coin
Previously, the ratio of coins A and B in giving each needs to be calculated. In this case, it is calculated from set 1 to 5. Then the results could be seen in the following table.
| Coin Tosses | E | Coin A Probability | Coin B Probability |
|---|---|---|---|
| HTTTHHTHTH | 5H 5T | 0.45 | 0.55 |
| HHHHTHHHHH | 9H 1T | 0.80 | 0.20 |
| HTHHHHHTHH | 8H 2T | 0.73 | 0.27 |
| HTHTTTHHTT | 4H 6T | 0.35 | 0.27 |
| THHHTHHHTH | 7H 3T | 0.65 | 0.35 |
After that, you need to estimate the total number of H for each coin [Fig 3(5)]. It is calculated based on the coin ratio above. To calculate “total heads and tails” for coin x, it is similar to the “complete data”. The method is quite easy, you just need to multiply the ratio of each coin to the number of heads in each , the results are shown in the following table.
| Coin Tosses | E | Estimated H for Coin A | Estimated H for Coin B |
|---|---|---|---|
| HTTTHHTHTH | 5H 5T | 5 * 0.45 = 2.25 | 5 * 0.55 = 2.75 |
| HHHHTHHHHH | 9H 1T | 9 * 0.80 = 7.2 | 9 * 0.20 = 1.8 |
| HTHHHHHTHH | 8H 2T | 8 * 0.73 = 5.84 | 8 * 0.27 = 2.16 |
| HTHTTTHHTT | 4H 6T | 4 * 0.35 = 1.4 | 4 * 0.65 = 2.6 |
| THHHTHHHTH | 7H 3T | 7 * 0.65 = 4.55 | 7 * 0.35 = 2.45 |
If you want, you can also calculate the tails for each coin as in the table above. But that is not necessary, because you can use another straightforward approach.
Until this step, you already have the E-Step calculations. Just a little bit more effort to finish your calculation in the M-Step.
4. M-Step
The results from the E-step can be used to improve the parameter. Here, we can use the maximum likelihood estimation (MLE) equation similar to the “completed data”.
As I said before, that it’s not necessary to calculate the tails for each coin; then you sum the heads and tails for each coin. Because each set contains 10 tosses, you just need to multiply the coin ratio with 10. That way, you could get the total estimated tosses from. Therefore:
![\begin{aligned} \theta_{A}' &= \dfrac{2.25 + 7.2 + 5.84 + 1.4 + 4.55}{10 * ( 0.45 + 0.8 + 0.73 + 0.35 + 0.65 )} \\[12pt] &= 0.713 \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-788b800c9da618fe1d2810c323e46e1f_l3.svg "Rendered by QuickLaTeX.com")
![\begin{aligned} \theta_{B}' &= \dfrac{2.75 + 1.8 + 2.16 + 2.6 + 2.45}{10 * ( 0.55 + 0.2 + 0.27 + 0.65 + 0.35 )} \\[12pt] &= 0.581 \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-445985f36d1438e9b4193683e301d0e9_l3.svg "Rendered by QuickLaTeX.com")
Finally, the both parameter of and for the first iteration have been improved [Fig 3(2)]. For the next iteration, the E-Step will use this new parameter value; and re-improved at the next M-step. This iteration will always repeat the E-step and M-step, until it reaches any stop condition.
5. Stopping condition and the final result
The iteration of the E-Step and M-Step, will be repeated until they meet the stopping condition. Commonly, the EM algorithm has two options of stopping condition, which are:
- Maximum iteration: means that, the EM Algorithm will stop if a certain number of iterations has been reached. For example, the maximum iteration is set to 10 iterations, then the EM Algorithm will not be more than 10 iterations. Or,
- Convergence threshold: means that, the M-step gives no significant parameter improvement; compared to the improvement in the previous iteration. The changes are very small below our threshold.
The final result of EM algorithm
In the EM case example above, the parameter improvement in each iteration can be seen in the following table:
| Iteration | θA | θB | Differences |
|---|---|---|---|
| 0 | 0.6 | 0.5 | 0.7810 |
| 1 | 0.713 | 0.581 | 0.1390 |
| 2 | 0.745 | 0.569 | 0.0342 |
| 3 | 0.768 | 0.550 | 0.0298 |
| 4 | 0.783 | 0.535 | 0.0212 |
| 5 | 0.791 | 0.526 | 0.0120 |
| 6 | 0.795 | 0.522 | 0.0057 |
| 7 | 0.796 | 0.521 | 0.0014 |
| 8 | 0.796 | 0.520 | 0.0010 |
| 9 | 0.796 | 0.520 | 0.0000 |
To calculate the differences or improvements in each iteration, you can use the Euclidean Distance equation, which is:
![d(q,p) = \sqrt{(q_{1}-p_{1})^2 + (q_{2}-p_{2})^2 + … + (q_{n}-p_{n})^2} \\[12pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-1204c880cfb0e425eba1cba3203f4f37_l3.svg "Rendered by QuickLaTeX.com")
In your case, an examples from iteration 1 to iteration 2 is:
![\begin{aligned} d(\theta,\theta') &= \sqrt{(\theta_{A}-\theta_{A}')^2 + (\theta_{B}-\theta_{B}')^2} \\[12pt] d(iter1,iter2) &= \sqrt{(0.713-0.745)^2 + (0.581-0.569} \\[12pt] &= 0.0342 \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-48a1562771c0906536e775b66588f61f_l3.svg "Rendered by QuickLaTeX.com")
The final results will be taken, if one of the stop condition has been reached. It doesn’t matter which one is the first reached. For example, let’s just say that the maximum iteration limit is set to 10 iterations. It has been seen that the iteration above has been done 10 iterations (starting iterations from 0 to 9). However, if the Convergence Threshold set to a minimum of 0.001, then the iteration will stop at the 8th iteration. It because the convergence limit has been reached first, before the maximum iteration.
So in our case, in 8th iteration, the final result obtained for coin A is  , and for coin B is
, and for coin B is  .
.
Weaknesses of the EM algorithm
Every algorithm has weaknesses, without any doubt; as well as the EM algorithm.
Every iteration in the EM algorithm, in general, will always improve the parameter closer to the local maximum likelihood. In other words, the EM algorithm will guarantee convergence, but will not guarantee to give a global maximum likelihood. And also there is no guarantee that you will get the maximum likelihood estimation (MLE).
In some conditions, the EM algorithm may give unexpected results. for example, if we set the initial parameter with the same number,  .[7] Then the results are:
.[7] Then the results are:
| Iteration | θA | θB | Diff |
|---|---|---|---|
| 0 | 0.3 | 0.3 | 0.7071 |
| 1 | 0.666 | 0.666 | 0.2263 |
| 2 | 0.666 | 0.666 | 0 |
| 3 | 0.666 | 0.666 | 0 |
| 4 | 0.666 | 0.666 | 0 |
It appears that there are no parameter improvements. For more details, try looking at Fig 4. “Case 1” is the normal case in the previous chapters, and “Case 2” is the case where we use the same initial parameter values.

To avoid this, it’s best to do some experiments with several different initial parameters. In general, most of these values will point to the same local optimum, and maybe one of them can achieve the global optimum.
The improvements of EM algorithm
Well, usually every algorithm can be refined with other improvements. It may improve accuracy when solving your case.
There are many things you can do, to improve this EM algorithm. For example:
- Use another method to determine the initial parameter values, rather than random values. Usually, this can reduce the number of EM iterations.
- You can also use other methods to calculate the probabilities in E-steps according to the type of data distribution you have.
References
- [1]D. R. Kishor and N. B. Venkateswarlu, “A Novel Hybridization of Expectation-Maximization and K-Means Algorithms for Better Clustering Performance,” International Journal of Ambient Computing and Intelligence, pp. 47–74, Jul. 2016, doi: 10.4018/ijaci.2016070103.
- [2]J. Garriga, J. R. B. Palmer, A. Oltra, and F. Bartumeus, “Expectation-Maximization Binary Clustering for Behavioural Annotation,” PLoS ONE, p. e0151984, Mar. 2016, doi: 10.1371/journal.pone.0151984.
- [3]J. Hui, “Machine Learning — Expectation-Maximization Algorithm (EM),” Medium, Aug. 14, 2019. https://medium.com/@jonathan_hui/machine-learning-expectation-maximization-algorithm-em-2e954cb76959 (accessed Mar. 04, 2020).
- [4]C. B. Do and S. Batzoglou, “What is the expectation maximization algorithm?,” Nat Biotechnol, pp. 897–899, Aug. 2008, doi: 10.1038/nbt1406.
- [5]K. Rosaen, “Expectation Maximization with Coin Flips,” Karl Rosaen: ML Study, Dec. 22, 2016. http://karlrosaen.com/ml/notebooks/em-coin-flips/ (accessed Jan. 14, 2019).
- [6]stackexchange user, “Answer on “When to use Total Probability Rule and Bayes’ Theorem”,” Mathematics Stack Exchange, Sep. 28, 2014. https://math.stackexchange.com/questions/948888/when-to-use-total-probability-rule-and-bayes-theorem (accessed Mar. 02, 2020).
- [7]A. Abid, “Gently Building Up The EM Algorithm,” GitHub: abidlabs, Mar. 01, 2018. https://abidlabs.github.io/EM-Algorithm/ (accessed Feb. 28, 2020).
Fig. 1 taken by Dennis Kwaria in wikimedia commons.


