Terakhir diperbarui pada Juni 10, 2022
Bagi orang yang tidak begitu fokus pada dunia matematika, mempelajari satu algoritma bisa sampai berminggu-minggu. Apalagi dengan banyaknya hal yang tidak kita ketahui. Termasuk saat mempelajari Algoritma Ekspektasi-Maksimisasi (Expectation–Maximization Algorithm) atau biasa disingkat menjadi “EM”. Tapi tenang, mungkin penjelasan tentang algoritma EM berikut lebih intuitif, dan dapat dengan mudah dicerna.
Algoritma EM mulai sering digunakan pada pemelajaran mesin (machine learning) sebagai salah satu metode untuk pengelompokan data (data clustering) [1], [2]. Salah satu permasalahan yang muncul pada saat pengelompokan data yaitu tidak diketahuinya label pada data. Misal jika kita mengetahui A, maka kita bisa menghitung B. Atau sebaliknya, Jika kita mengetahui B, kita dapat menghitung A. Namun terkadang A dan B tidak diketahui. Disinilah algoritma EM sangat membantu dalam menyelesaikan masalah tersebut [3].
Algoritma EM ini sebenarnya adalah metode perulangan yang melibatkan tahap Ekspektasi (E-step) dan tahap Maksimisasi (M-step), hingga menemukan nilai parameter lokal paling memungkinkan (Maximum Likelihood). Umumnya digunakan pada beberapa distribusi atau model statistik. Namun lebih kepada kasus dimana ada satu atau lebih variabel yang tidak diketahui. Variabel ini bisa disebut sebagai variabel laten.
Artinya, kita dapat menggunakan algoritma EM jika:
- Kita memiliki dataset yang tidak lengkap (misal, tidak memiliki data grup atau label dalam data tsb), tetapi kita perlu memprediksi parameter grup atau label tersebut.
- Grup atau label tersebut tidak pernah teramati atau tercatat, tetapi sangat penting dalam menjelaskan sebuah data. Hal ini disebut variabel “laten”, berarti tersembunyi atau tidak nampak.
Catatan: beberapa teori yang mungkin perlu kamu pelajari yaitu probabilitas variabel acak binomial dan probabilitas kondisional/bersyarat.
Contoh Kasus algoritma EM
Untuk mempermudah pemahaman tentang EM, disini kita dapat menggunakan contoh distribusi hasil lemparan koin.[4]

Semisal, saya memiliki 2 koin, Koin A dan Koin B. Saya akan memilih koin secara acak, entah koin A atau B sebanyak 5x. Setiap pemilihan koin, disertai dengan melempar koin 10x dengan hasil sebagai berikut:
- Set 1:
H T T T H H T H T H(5H 5T) - Set 2:
H H H H T H H H H H(9H 1T) - Set 3:
H T H H H H H T H H(8H 2T) - Set 4:
H T H T T T H H T T(4H 6T) - Set 5:
T H H H T H H H T H(7H 3T)
Keterangan: untuk menyesuaikan dengan sumber jurnal, disini munculnya sisi gambar menggunakan “H” atau Head, dan munculnya sisi angka menggunakan “T” atau Tail. Dimana probabilitas munculnya “H” untuk setiap koin ini kita nyatakan dengan theta atau “ “.
“.
Pertanyaannya, bagaimana kamu mengestimasi probabilitas munculnya “H” pada setiap koinnya? [5]
Data Lengkap
Sekarang, semisal pada kasus di atas, kamu mendapatkan lebih banyak informasi atau data. Saya memberitahukan koin mana yang saya gunakan pada tiap setnya. Maka, data yang kamu miliki berubah menjadi seperti berikut:
- Set 1, Koin B:
H T T T H H T H T H(5H 5T) - Set 2, Koin A:
H H H H T H H H H H(9H 1T) - Set 3, Koin A:
H T H H H H H T H H(8H 2T) - Set 4, Koin B:
H T H T T T H H T T(4H 6T) - Set 5, Koin A:
T H H H T H H H T H(7H 3T)
Dengan data yang lengkap seperti ini, kamu dapat dengan mudah menghitung probabilitas munculnya “H” pada setiap koinnya. Hal ini dikarenakan identitas koin yang digunakan tiap setnya sudah diketahui. Maka,
dengan diketahuinya total koin A = 24H 6T, dan dalam 3 set dengan total 30 kali lemparan, maka
 .
.
Begitu juga dengan total koin B = 9H 11T, dan dalam 2 set dengan total 20 kali lemparan, maka
 .
.
Persamaan yang mudah ini dikenal dengan nama maximum likelihood estimation (MLE), atau estimasi kemungkinan maksimum.
Dimana

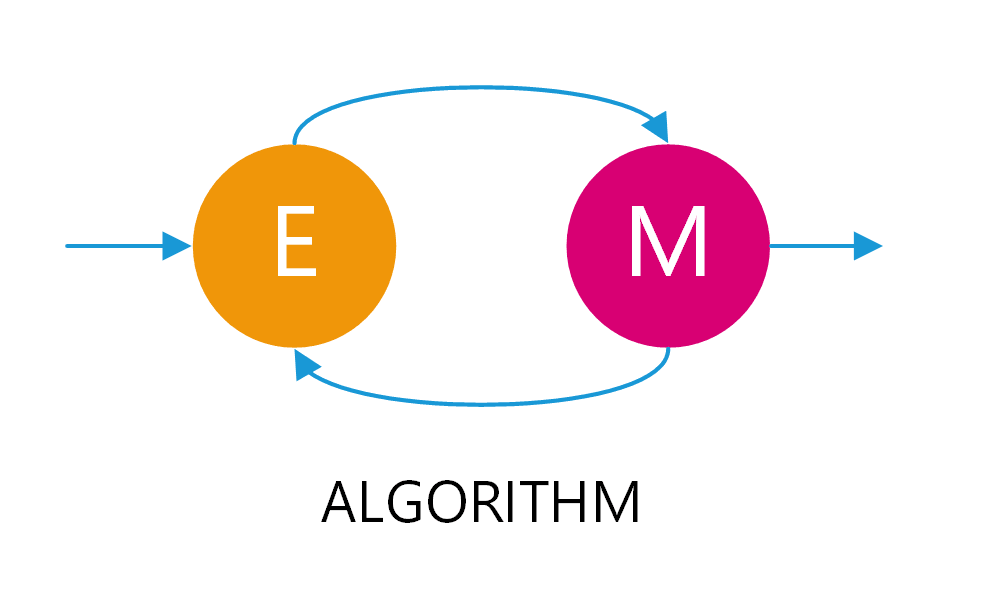
Gambaran umum algoritma EM
Alur algoritma EM
Sebelum kembali ke kasus awal, mari saya jelaskan secara singkat tahapan algoritma EM. Jadi kamu dapat membayangkan rute algoritma EM dengan mudah saat membaca hingga akhir.

Saat menggunakan algoritma EM, ada beberapa tahapan yang harus dilalui.
- Mendefinisikan variabel laten
- Tebakan awal / pemilihan nilai parameter awal
- E-Step
- M-Step
- Kondisi berhenti dan hasil akhir
Sebenarnya, poin utama EM yaitu iterasi atau perulangan antara E-step dan M-step. Coba lihat Gambar 2, terkait adanya perulangan di bagian E-step dan M-step. Perulangan ini merupakan bentuk estimasi ulang setiap parameternya.
Di dalam algoritma EM

Gambar 3 di atas menggambarkan bagaimana perhitungan di dalam EM pada kasus kita; di mana kamu tidak tahu identitas koin. Pendekatannya, yaitu dengan mendistribusikan jumlah kepala (H) untuk setiap set; yang proporsional berdasarkan parameter untuk setiap koin. Oleh karena itu, pertama-tama, kamu perlu menebak parameter awal [Gambar 3(1)] untuk setiap koin. Kemudian, (awalnya) parameter saat ini [Gambar 3(2)] merupakan tebakan awal kamu.
Lalu, tahap E-Step merupakan taksiran probabilitas identitas koin yang digunakan di setiap set [Gambar 3(3)], berdasar parameter saat ini. Misalnya, berapa peluang koin A mendapatkan 8H 2T dalam 10 kali pelemparan (set 3).
Kemudian, membandingkan peluang koin A dan koin B; berdasarkan probabilitas total mereka [Gambar 3(4)]. Sebagai contoh, untuk mendapatkan hasil sebuah set 8H 2T, penggunaan koin A memiliki probabilitas 73%, dibandingkan dengan koin B yang hanya memiliki probabilitas 27%. Ini adalah cara memperkirakan probabilitas identitas koin yang digunakan di setiap set.
Selanjutnya, probabilitas identitas dapat digunakan untuk memperkirakan jumlah H (dan T) untuk setiap koin, dalam setiap set [Gambar 3(5)]. Misalnya, 8 Kepala (8H) itu dibagi secara proporsional 73% untuk koin A dan 27% untuk koin B. Dalam contoh ini, koin A akan mendapat 5,84 H dan koin B mendapat 2,16 H.
Terakhir, total estimasi H dan T tiap koin, digunakan untuk menghitung ulang nilai parameter pada tahap M-Step. Dengan kata lain, nilai paramater [Gambar 3(2)] akan dihitung ulang, berdasarkan hasil perkiraan variabel tersembunyi dan data yang ada atau teramati.
Perulangan ini akan terus berlanjut dan akan berhenti saat sudah mencapai batas “maksimum iterasi” atau, hingga terjadi konvergensi. Saat perulangan sudah selesai, hasil yang diperoleh merupakan estimasi parameter paling mendekati lokal optimum.
Konvergensi disini dapat diartikan bahwa hasil perulangan sudah tidak banyak berubah. Dengan kata lain, perbedaan hasil antara iterasi saat ini dan iterasi berikutnya sudah di bawah batas ambang.
1. Pendefinisian variabel laten
Nah, kembali ke kasus awal, dimana informasi yang kamu miliki yaitu:
- Set 1:
H T T T H H T H T H(5H 5T) - Set 2:
H H H H T H H H H H(9H 1T) - Set 3:
H T H H H H H T H H(8H 2T) - Set 4:
H T H T T T H H T T(4H 6T) - Set 5:
T H H H T H H H T H(7H 3T)
Pertama, kamu harus mendefinisikan variabel apa saja yang dibutuhkan, namun tidak ada dalam data.
Tujuan akhirnya yaitu mengestimasi probabilitas munculnya “H” pada setiap koinnya. Namun hal ini tidak dapat di hitung apabila identitas koin tidak diketahui. Maka, perlu untuk mengetahui identitas koin mana yang digunakan tiap setnya. Oleh karena itu, identitas koin inilah yang menjadi variabel laten.
Saat ini, selain data 5 set di atas, kamu hanya tahu bahwa saya menggunakan dua koin, yaitu koin A dan koin B.
2. Pemilihan nilai parameter awal
Dengan probabilitas munculnya “H” untuk setiap koin ini yang telah nyatakan dengan theta atau . Saat ini hanya ada koin A dan koin B dengan nilai parameter  dan
dan  yang belum diketahui.
yang belum diketahui.
Sebelum mengestimasi menggunakan perulangan EM, terlebih dahulu kamu perlu memberikan estimasi awal terhadap kedua parameter tersebut [Gambar 3(1)]. Jadi kamu boleh saja memilih secara acak untuk setiap  , misal:
, misal:
 dan
dan  ,
,
atau  dan
dan  ,
,
atau dan  ,
,
atau dan ,
atau angka-angka lainnya antara 0 dan 1 (terkait probabilitas).
Oh, saya tekankan bahwa pemilihan angka dan ini tidak berhubungan, misal dijumlah harus = 1, TIDAK! Angka ini merupakan nilai individual probabilitas munculnya “H” setiap koin.
 , artinya koin a memiliki probabilitas munculnya H sebanyak 60% dibanding 40% probabilitas munculnya T pada koin yang sama (A). Tidak ada hubungannya dengan pemilihan nilai atau untuk koin B. Jadi meski telah menentukan , untuk boleh saja
, artinya koin a memiliki probabilitas munculnya H sebanyak 60% dibanding 40% probabilitas munculnya T pada koin yang sama (A). Tidak ada hubungannya dengan pemilihan nilai atau untuk koin B. Jadi meski telah menentukan , untuk boleh saja  ,
,  ,
,  ,
,  atau angka lainnya yang bahkan beberapa digit di belakang koma.
atau angka lainnya yang bahkan beberapa digit di belakang koma.
Oke cukup, sekarang, anggap saja kamu sudah menentukan nilai awal secara acak, yaitu:
dan
3. E-Step
Sekarang kamu sudah memiliki sebagian variabel yang dibutuhkan. Jadi, kamu bisa mulai menghitung probabilitas koin mana yang digunakan pada setiap set nya.
Setiap set, yang berisi munculnya H dan T, dapat kita nyatakan dengan  . Lalu, pemilihan koin A dinyatakan dengan
. Lalu, pemilihan koin A dinyatakan dengan  dan pemilihan koin B dinyatakan dengan
dan pemilihan koin B dinyatakan dengan  .
.
Dalam E-Step, awalnya kamu perlu mengetahui probabilitas munculnya sebuah set menggunakan koin A dan B. Semisal dengan koin A, probabilitas munculnya E sekitar 0.5, dan dengan koin B sekitar 0.25. Maka secara keseluruhan, probabilitas bahwa E menggunakan koin a dibanding koin B adalah 2:1, atau 66,6% : 33,3%. Perbandingan inilah yang akan kita cari dalam E-Step. Yang mana, hasil perbandingan tersebut digunakan untuk mengestimasi perkiraan jumlah H dan T untuk setiap koin, dalam tiap setnya.
Probabilitas memunculkan E
Sekarang, dengan contoh dari set 3, =HTHHHHHTHH (8H 2T). Jika yang berarti probabilitas munculnya  (dan
(dan  ) menggunakan koin A. Maka dalam sebuah set, seberapa besar probabilitas
) menggunakan koin A. Maka dalam sebuah set, seberapa besar probabilitas  akan muncul menggunakan koin A? Inilah yang perlu kita perkirakan terlebih dahulu [Gambar 3(3)]. Pertanyaan ini dapat disimbolkan dengan
akan muncul menggunakan koin A? Inilah yang perlu kita perkirakan terlebih dahulu [Gambar 3(3)]. Pertanyaan ini dapat disimbolkan dengan  .
.
Begitu juga dengan probabilitas koin B memunculkan set , kita nyatakan dengan  . Hal ini berkaitan dengan teori probabilitas variabel acak binomial, yang persamaannya yaitu:
. Hal ini berkaitan dengan teori probabilitas variabel acak binomial, yang persamaannya yaitu:

dimana:
 = probabilitas munculnya menggunakan koin x.
= probabilitas munculnya menggunakan koin x. = total lemparan dalam satu set .
= total lemparan dalam satu set . = total jumlah munculnya H dalam satu set .
= total jumlah munculnya H dalam satu set .  = probabilitas munculnya H menggunakan koin x.
= probabilitas munculnya H menggunakan koin x.
Maka, kita dapat menghitung probabilitas munculnya menggunakan koin A dan B sebagai berikut:
![P(E_{8H2T}|Z_{A})= \dfrac{10!}{8!\;2!}\;{0.6}^{8}\;0.4^{2}=0.121 \\[4pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-66117536e7b0bcc9c6a5c4da3558cac0_l3.svg "Rendered by QuickLaTeX.com")

Rasio koin A dan B memunculkan E
Oke, sebenarnya kita tidak perlu menghitung hasil akhir persamaan di atas. Karena yang kita butuhkan lebih ke perbandingan probabilitas koin yang digunakan, A atau B [Gambar 3(4)]. Maka, menurut teori Bayes’ dan hukum probabilitas total, kita dapat menentukan rasio probabilitas koin A dibanding koin B. Persamaannya yaitu:[6]
![P(Z_{x}|E)= \dfrac{\textit{probabilitas munculnya E pada koin x}}{\textit{total probabilitas munculnya E dengan koin x dan y}} \\[12pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-8c49328a09254c342d5ba5fce6989003_l3.svg "Rendered by QuickLaTeX.com")
![P(Z_{x}|E)= \dfrac{P(E|Z_{x})P(Z_{x})}{P(E|Z_{x})P(Z_{x})+P(E|Z_{y})P(Z_{y})} \\[8pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-bce552ce1a85d4df2e62b31fffa7da28_l3.svg "Rendered by QuickLaTeX.com")
dimana:
 = probabilitas set menggunakan koin x (dibanding y).
= probabilitas set menggunakan koin x (dibanding y). = probabilitas pemilihan koin x (dalam kasus kita, koin A atau B).
= probabilitas pemilihan koin x (dalam kasus kita, koin A atau B).
Namun, karena kasusnya hanya ada 2 koin, koin A dan B, maka kemungkinan saya memilih salah satunya adalah 50:50. Maka  .
.
Dengan begitu, untuk koin A, kita dapat menyederhanakan persamaan di atas menjadi:
![\begin{aligned}P(Z_{A}|E) &= \dfrac{P(E|Z_{A})\cancel{P(Z_{A})}}{P(E|Z_{A})\cancel{P(Z_{A})}+P(E|Z_{B})\cancel{P(Z_{B})}} \\[12pt] &= \dfrac{P(E|Z_{A})}{P(E|Z_{A})+P(E|Z_{B})} \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-54c5a1f58afd9deb993e9c109afb5038_l3.svg "Rendered by QuickLaTeX.com")
![\begin{aligned} P(Z_{A}|E_{8H2T}) &= \dfrac{\cancel{\dfrac{10!}{8!\;2!}}\;{0.6}^{8}\;0.4^{2}}{\cancel{\dfrac{10!}{8!\;2!}}\;{0.6}^{8}\;0.4^{2}+\cancel{\dfrac{10!}{8!\;2!}}\;{0.5}^{8}\;0.5^{2}} \\[24pt] &= \dfrac{{0.6}^{8}\;0.4^{2}}{{0.6}^{8}\;0.4^{2}+{0.5}^{8}\;0.5^{2}} \\[12pt] &= 0.73 \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-855d9ea630e406925cd3297c6eb38bb2_l3.svg "Rendered by QuickLaTeX.com")
Selanjutnya, untuk koin B, menjadi:
![\begin{aligned} P(Z_{B}|E_{8H2T}) &= \dfrac{\cancel{\dfrac{10!}{8!\;2!}}\;{0.5}^{8}\;0.5^{2}}{\cancel{\dfrac{10!}{8!\;2!}}\;{0.6}^{8}\;0.4^{2}+\cancel{\dfrac{10!}{8!\;2!}}\;{0.5}^{8}\;0.5^{2}} \\[24pt] &= \dfrac{{0.5}^{8}\;0.5^{2}}{{0.6}^{8}\;0.4^{2}+{0.5}^{8}\;0.5^{2}} \\[12pt] &= 0.27 \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-e5903f648cb1dd3c03ee4b080b46879f_l3.svg "Rendered by QuickLaTeX.com")
Estimasi H untuk tiap koin
Nah pada sub bab sebelumnya, rasio koin A dan B dalam memunculkan setiap set perlu dihitung semua. Dalam kasus ini mulai dari set 1 hingga set 5. Hasil mungkin dapat dilihat pada tabel berikut.
| Hasil Lemparan | E | Probabilitas koin A | Probabilitas koin B |
|---|---|---|---|
| HTTTHHTHTH | 5H 5T | 0.45 | 0.55 |
| HHHHTHHHHH | 9H 1T | 0.80 | 0.20 |
| HTHHHHHTHH | 8H 2T | 0.73 | 0.27 |
| HTHTTTHHTT | 4H 6T | 0.35 | 0.27 |
| THHHTHHHTH | 7H 3T | 0.65 | 0.35 |
Setelah itu, kamu perlu mengestimasi total H untuk setiap koin [Gambar 3(5)]. Hampir sama seperti pada bab “data lengkap” untuk menghitung “total H dan T” untuk koin x. Caranya cukup mudah, kamu hanya tinggal mengkalikan rasio koin x dengan jumlah H pada setiap set E, yang hasilnya terlihat pada tabel berikut.
| Hasil Lemparan | E | Estimasi H koin A | Estimasi H koin B |
|---|---|---|---|
| HTTTHHTHTH | 5H 5T | 5 * 0.45 = 2.25 | 5 * 0.55 = 2.75 |
| HHHHTHHHHH | 9H 1T | 9 * 0.80 = 7.2 | 9 * 0.20 = 1.8 |
| HTHHHHHTHH | 8H 2T | 8 * 0.73 = 5.84 | 8 * 0.27 = 2.16 |
| HTHTTTHHTT | 4H 6T | 4 * 0.35 = 1.4 | 4 * 0.65 = 2.6 |
| THHHTHHHTH | 7H 3T | 7 * 0.65 = 4.55 | 7 * 0.35 = 2.45 |
Jika kamu mau, kamu juga bisa menghitung T untuk setiap koin seperti pada tabel di atas. Tapi itu tidak diperlukan pada perhitungan kita karena kita akan menggunakan pendekatan lain.
4. M-Step
Kali ini, hasil dari perhitungan E-step di atas, dapat digunakan untuk memperbaiki nilai parameter . Disini, kita dapat menggunakan persamaan maximum likelihood estimation (MLE), atau estimasi kemungkinan maksimum seperti pada kasus “Data lengkap”.
Karena setiap koin akan mendapat bagian tiap set secara proporsional, dan dimana setiap set berisi 10 lemparan. Maka:
![\begin{aligned} \theta_{A}' &= \dfrac{2.25 + 7.2 + 5.84 + 1.4 + 4.55}{10 * ( 0.45 + 0.8 + 0.73 + 0.35 + 0.65 )} \\[12pt] &= 0.713 \\[12pt] \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-788b800c9da618fe1d2810c323e46e1f_l3.svg "Rendered by QuickLaTeX.com")
![\begin{aligned} \theta_{B}' &= \dfrac{2.75 + 1.8 + 2.16 + 2.6 + 2.45}{10 * ( 0.55 + 0.2 + 0.27 + 0.65 + 0.35 )} \\[12pt] &= 0.581 \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-445985f36d1438e9b4193683e301d0e9_l3.svg "Rendered by QuickLaTeX.com")
Nah, sampai sini, nilai parameter dan telah diperbaiki [Gambar 3(2)]. Selanjutnya kembali lagi ke perhitungan E-Step, namun menggunakan nilai parameter yang baru ini. Dan alur ini akan selalu berulang E-M-E-M-E-M… hingga mencapai kondisi berhenti.
5. Kondisi berhenti dan hasil akhir
Perulangan E-Step dan M-Step di atas, akan terus berlanjut hingga menemui kriteria berhenti. Algoritma EM memiliki dua kriteria berhenti, yaitu:
- Iterasi maksimum: Artinya, alur E-step dan M-step akan berhenti hingga jumlah iterasi tertentu telah tercapai. Misal iterasi maksimum ditentukan 10 kali iterasi, maka iterasi E dan M tidak akan lebih dari 10x. Atau,
- Batas Konvergensi: Artinya, hasil perbaikan nilai parameter M-step sudah tidak banyak berubah dibanding dengan nilai pada iterasi sebelumnya. Dalam artian perubahan sudah sangat kecil di bawah batas minimum.
Hasil akhir algoritma EM
Pada contoh kasus EM di atas, hasil perbaikan nilai parameter tiap iterasinya dapat dilihat pada tabel berikut:
| Iterasi ke- | θA | θB | Perubahan |
|---|---|---|---|
| 0 | 0.6 | 0.5 | 0.7810 |
| 1 | 0.713 | 0.581 | 0.1390 |
| 2 | 0.745 | 0.569 | 0.0342 |
| 3 | 0.768 | 0.550 | 0.0298 |
| 4 | 0.783 | 0.535 | 0.0212 |
| 5 | 0.791 | 0.526 | 0.0120 |
| 6 | 0.795 | 0.522 | 0.0057 |
| 7 | 0.796 | 0.521 | 0.0014 |
| 8 | 0.796 | 0.520 | 0.0010 |
| 9 | 0.796 | 0.520 | 0.0000 |
Untuk perhitungan perubahan tiap iterasinya, kamu dapat menggunakan persamaan umum seperti Euclidean Distance, yaitu:
![d(q,p) = \sqrt{(q_{1}-p_{1})^2 + (q_{2}-p_{2})^2 + … + (q_{n}-p_{n})^2} \\[12pt]](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-1204c880cfb0e425eba1cba3203f4f37_l3.svg "Rendered by QuickLaTeX.com")
atau dalam kasus ini, contoh perubahan dari iterasi 1 ke iterasi 2 yaitu:
![\begin{aligned} d(\theta,\theta') &= \sqrt{(\theta_{A}-\theta_{A}')^2 + (\theta_{B}-\theta_{B}')^2} \\[12pt] d(iter1,iter2) &= \sqrt{(0.713-0.745)^2 + (0.581-0.569} \\[12pt] &= 0.0342 \end{aligned}](https://www.indowhiz.com/articles/wp-content/ql-cache/quicklatex.com-48a1562771c0906536e775b66588f61f_l3.svg "Rendered by QuickLaTeX.com")
Hasil akhir yang akan diambil adalah yang terlebih dahulu mencapai kondisi berhenti. Anggap saja batas iterasi maksimum adalah 10x. Telah terlihat bahwa iterasi di atas telah dilakukan 10x (mulai iterasi 0 sampai 9). Namun, jika dalam Batas Konvergensi juga ditentukan, dengan perubahan minimumnya 0.001, maka iterasi akan berhenti pada iterasi ke-8. Hal ini dikarenakan batas konvergensi telah tercapai sebelum batas iterasi.
Jadi pada kasus kita, hasil akhir yang diperoleh untuk koin A yaitu  , dan untuk koin B yaitu
, dan untuk koin B yaitu  .
.
Kelemahan algoritma EM
Setiap algoritma pasti memiliki kelemahan, begitu juga dengan algoritma EM.
Setiap perulangan dalam algoritma EM, secara umum akan selalu memperbaiki nilai parameter mendekati lokal optimum. Dengan kata lain, dengan algoritma EM akan menjamin konvergensi, tetapi tidak akan menjamin ke arah global optimum. Dan juga tidak ada jaminan akan mendapatkan maximum likelihood estimation (MLE).
Contoh dimana algoritma EM tidak sesuai harapan yaitu, semisal tebakan awal kita tentukan dengan angka yang sama,  .[7] Maka hasil tiap iterasinya akan seperti berikut:
.[7] Maka hasil tiap iterasinya akan seperti berikut:
| Iterasi ke- | θA | θB | Perubahan |
|---|---|---|---|
| 0 | 0.3 | 0.3 | 0.7071 |
| 1 | 0.666 | 0.666 | 0.2263 |
| 2 | 0.666 | 0.666 | 0 |
| 3 | 0.666 | 0.666 | 0 |
| 4 | 0.666 | 0.666 | 0 |
Terlihat bahwa tidak ada peningkatan nilai parameter. Untuk lebih jelasnya, coba lihat pada Gambar 4. Dimana “Case 1” merupakan kasus pada bab-bab sebelumnya, dan “Case 2” dimana kita menggunakan nilai parameter awal yang sama.

Untuk menghindari hal ini, sebaiknya lakukan beberapa eksperimen dengan beberapa nilai parameter awal yang berbeda. Secara umum, kebanyakan nilai tersebut akan mengarahkan ke lokal optimum yang sama, dan mungkin salah satunya bisa mencapai nilai global optimum.
Penyempurnaan algoritma EM
Nah, biasanya setiap algoritma dapat di sempurnakan dengan tambahan-tambahan lainnya. Hal ini mungkin dapat meningkatkan akurasi dalam menyelesaikan kasusmu.
Ada banyak hal yang dapat kamu lakukan untuk menyempurnakan algoritma EM ini, misalnya:
- Gunakan metode lain untuk menentukan nilai parameter awal, selain nilai acak. Hal ini umumnya dapat mengurangi jumlah iterasi EM.
- Kamu juga bisa menggunakan metode lain untuk menghitung Probabilitas dalam E-step sesuai dengan jenis distribusi data yang kamu miliki.
Referensi
- [1]D. R. Kishor and N. B. Venkateswarlu, “A Novel Hybridization of Expectation-Maximization and K-Means Algorithms for Better Clustering Performance,” International Journal of Ambient Computing and Intelligence, pp. 47–74, Jul. 2016, doi: 10.4018/ijaci.2016070103.
- [2]J. Garriga, J. R. B. Palmer, A. Oltra, and F. Bartumeus, “Expectation-Maximization Binary Clustering for Behavioural Annotation,” PLoS ONE, p. e0151984, Mar. 2016, doi: 10.1371/journal.pone.0151984.
- [3]J. Hui, “Machine Learning —Expectation-Maximization Algorithm (EM),” Medium, Aug. 14, 2019. https://medium.com/@jonathan_hui/machine-learning-expectation-maximization-algorithm-em-2e954cb76959 (accessed Mar. 04, 2020).
- [4]C. B. Do and S. Batzoglou, “What is the expectation maximization algorithm?,” Nat Biotechnol, pp. 897–899, Aug. 2008, doi: 10.1038/nbt1406.
- [5]K. Rosaen, “Expectation Maximization with Coin Flips,” Karl Rosaen: ML Study, Dec. 22, 2016. http://karlrosaen.com/ml/notebooks/em-coin-flips/ (accessed Jan. 14, 2019).
- [6]stackexchange user, “Answer on ‘When to use Total Probability Rule and Bayes’’ Theorem”,’” Mathematics Stack Exchange, Sep. 28, 2014. https://math.stackexchange.com/questions/948888/when-to-use-total-probability-rule-and-bayes-theorem (accessed Mar. 02, 2020).
- [7]A. Abid, “Gently Building Up The EM Algorithm,” GitHub: abidlabs, Mar. 01, 2018. https://abidlabs.github.io/EM-Algorithm/ (accessed Feb. 28, 2020).
Gambar 1 diproduksi oleh Dennis Kwaria di wikimedia commons.


